Linux I/O 模型
- 阻塞 I/O
- 非阻塞 I/O
- 信号驱动 I/O:使用 signal 或 signalfd 注册 SIGIO 信号,收到信号通知处理 I/O 事件
- I/O 多路复用:select、poll、epoll
- 异步 I/O:aio_read、io_uring
I/O 多路复用
I/O 多路复用表示在单个线程中管理多个输入/输出通道的技术。
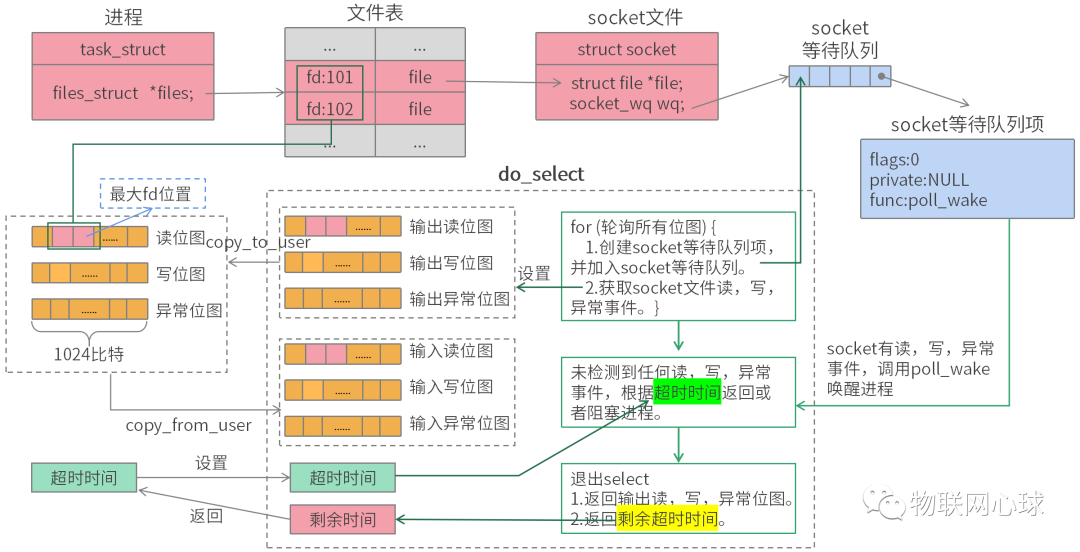
select
select 采用位图,分为读、写、异常位图。
用户程序预先将 socket 文件描述符注册至读、写、异常位图,然后调用 select 系统调用轮询位图中的 socket 的读、写、异常事件。
函数签名
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_SET(int fd, fd_set *set);
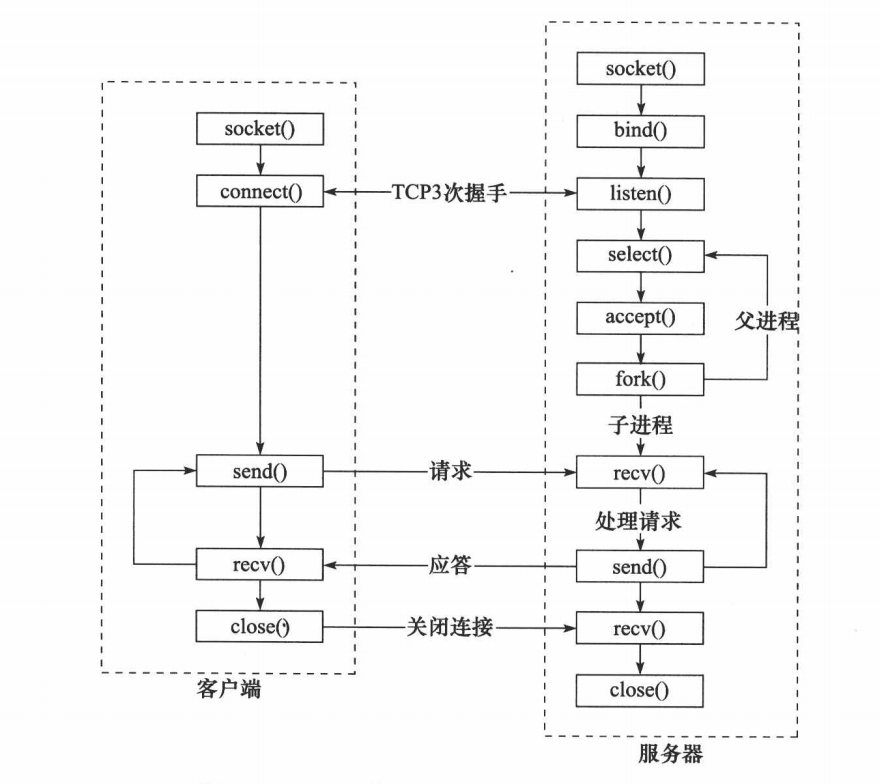
void FD_ZERO(fd_set *set);select 流程(多进程)
示例代码(仅示例阻塞模式下读取事件)
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/signal.h>
#include <sys/wait.h>
#include <sys/sendfile.h>
#include <sys/select.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <iostream>
#include <unordered_map>
int main() {
int sock_fd = ::socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
if (sock_fd == -1) { // 创建 socket 失败
std::cerr << "socket failed: " << errno << std::endl;
return -1;
}
struct sockaddr_in addr;
::memset(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET;
if (::inet_pton(AF_INET, "127.0.0.1", &(addr.sin_addr)) != 1) {
addr.sin_addr.s_addr = ::inet_addr("127.0.0.1");
}
addr.sin_port = htons(3000);
if (::bind(sock_fd, reinterpret_cast<struct sockaddr*>(&addr), sizeof(addr)) == -1) {
std::cerr << "bind failed" << errno << std::endl;
::close(sock_fd);
return -1;
}
if (::listen(sock_fd, 5) == -1) {
std::cerr << "listen failed" << errno << std::endl;
::close(sock_fd);
return -1;
}
std::cout << "server started..." << std::endl;
std::unordered_map<int, std::string> client_fds;
while (1) {
// 准备好需要交互的文件描述符列表
fd_set read_fds;
FD_ZERO(&read_fds);
FD_SET(sock_fd, &read_fds);
int maxfd = sock_fd;
for (auto&& [fd, addr]: client_fds) {
FD_SET(fd, &read_fds);
maxfd = std::max(maxfd, fd);
}
int res = ::select(maxfd + 1, &read_fds, NULL, NULL, NULL);
if (res == -1) {
if (errno == EINTR) {
continue;
}
std::cerr << "select failed" << errno << std::endl;
break;
}
if (res == 0) {
continue;
}
for (int i = 0; i <= maxfd; ++i) {
// 检测读事件
if (FD_ISSET(i, &read_fds)) {
if (i == sock_fd) { // 监听的 fd
struct sockaddr_in client_addr;
socklen_t client_addr_len = sizeof(sockaddr_in);
int client_fd = ::accept(sock_fd, reinterpret_cast<struct sockaddr*>(&client_addr), &client_addr_len);
if (client_fd == -1) {
std::cerr << "accept failed: " << errno << std::endl;
continue;
}
char ip_str[INET_ADDRSTRLEN] = {0};
inet_ntop(AF_INET, &(client_addr.sin_addr), ip_str, sizeof(client_addr));
std::string addr = ip_str; addr += ":" + std::to_string(ntohs(client_addr.sin_port));
std::cout << "accept: " << addr << std::endl;
client_fds.emplace(client_fd, std::move(addr));
} else {
std::string addr = client_fds[i];
char data[1024] = {0};
ssize_t rsize = ::recv(i, data, 1024, 0);
if (rsize == -1 || rsize == 0) {
std::cout << "close " << addr << " connect" << std::endl;
client_fds.erase(i);
::close(i);
continue;
}
std::cout << "Client(" << addr << "): " << data << std::endl;
std::cout << "Server: " << data << std::endl;
::send(i, data, rsize, 0);
}
}
}
}
for (auto&& [i, addr]: client_fds) {
::close(i);
}
::close(sock_fd);
return 0;
}poll
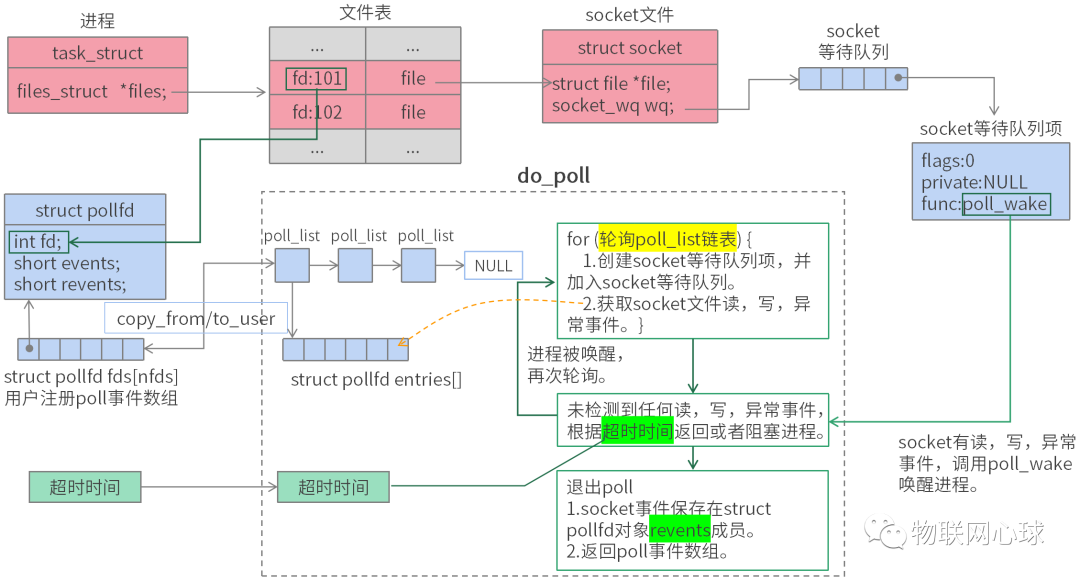
poll 机制与 select 机制类似,但是 poll 没有最大文件描述符数量的限制,因此在文件描述符数量较大时,poll 的效率会更高。
内核将传入得数据拆分为多个数组挂载在一条链表上,基于链表轮询每个 socket 的事件。
函数签名
int poll(struct pollfd *fds, nfds_t nfds, int timeout);示例代码(仅示例阻塞模式下读取事件)
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/signal.h>
#include <sys/wait.h>
#include <sys/sendfile.h>
#include <sys/poll.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <iostream>
#include <vector>
#include <unordered_map>
#include <algorithm>
int main() {
int sock_fd = ::socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
if (sock_fd == -1) { // 创建 socket 失败
std::cerr << "socket failed: " << errno << std::endl;
return -1;
}
struct sockaddr_in addr;
::memset(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET;
if (::inet_pton(AF_INET, "127.0.0.1", &(addr.sin_addr)) != 1) {
addr.sin_addr.s_addr = ::inet_addr("127.0.0.1");
}
addr.sin_port = htons(3000);
if (::bind(sock_fd, reinterpret_cast<struct sockaddr*>(&addr), sizeof(addr)) == -1) {
std::cerr << "bind failed" << errno << std::endl;
::close(sock_fd);
return -1;
}
if (::listen(sock_fd, 5) == -1) {
std::cerr << "listen failed" << errno << std::endl;
::close(sock_fd);
return -1;
}
std::cout << "server started..." << std::endl;
std::unordered_map<int, std::string> client_fds;
std::vector<struct pollfd> poll_fds = {
{ .fd = sock_fd, .events = POLLIN, .revents = 0 }
};
while (1) {
int res = ::poll(poll_fds.data(), poll_fds.size(), -1);
if (res == -1) {
if (errno == EINTR) {
continue;
}
std::cerr << "poll failed" << errno << std::endl;
break;
}
if (res == 0) {
continue;
}
std::vector<struct pollfd> new_poll_fds;
for (auto& poll_fd: poll_fds) {
// 检测读事件
if (poll_fd.revents & POLLIN) {
if (poll_fd.fd == sock_fd) {
struct sockaddr_in client_addr;
socklen_t client_addr_len = sizeof(sockaddr_in);
int client_fd = ::accept(sock_fd, reinterpret_cast<struct sockaddr*>(&client_addr), &client_addr_len);
if (client_fd == -1) {
std::cerr << "accept failed: " << errno << std::endl;
continue;
}
char ip_str[INET_ADDRSTRLEN] = {0};
inet_ntop(AF_INET, &(client_addr.sin_addr), ip_str, sizeof(client_addr));
std::string addr = ip_str; addr += ":" + std::to_string(ntohs(client_addr.sin_port));
std::cout << "accept: " << addr << std::endl;
new_poll_fds.push_back(
{ .fd = client_fd, .events = POLLIN, .revents = 0 }
);
client_fds.emplace(client_fd, std::move(addr));
} else {
std::string addr = client_fds[poll_fd.fd];
char data[1024] = {0};
ssize_t rsize = ::recv(poll_fd.fd, data, 1024, 0);
if (rsize == -1 || rsize == 0) {
std::cout << "close " << addr << " connect" << std::endl;
client_fds.erase(poll_fd.fd);
::close(poll_fd.fd);
poll_fd.fd = -1;
continue;
}
std::cout << "Client(" << addr << "): " << data << std::endl;
std::cout << "Server: " << data << std::endl;
::send(poll_fd.fd, data, rsize, 0);
}
} else if (poll_fd.revents & POLLHUP) {
::close(poll_fd.fd);
poll_fd.fd = -1;
}
}
// 删除数组中 fd 为 -1 的 pollfd
poll_fds.erase(
std::remove_if(poll_fds.begin(), poll_fds.end(),
[](auto&& poll_fd) { return poll_fd.fd == -1; }
), poll_fds.end()
);
// 监听集合加入新的文件描述符
poll_fds.insert(poll_fds.end(), new_poll_fds.begin(), new_poll_fds.end());
}
for (auto&& [i, addr]: client_fds) {
::close(i);
}
::close(sock_fd);
return 0;
}epoll
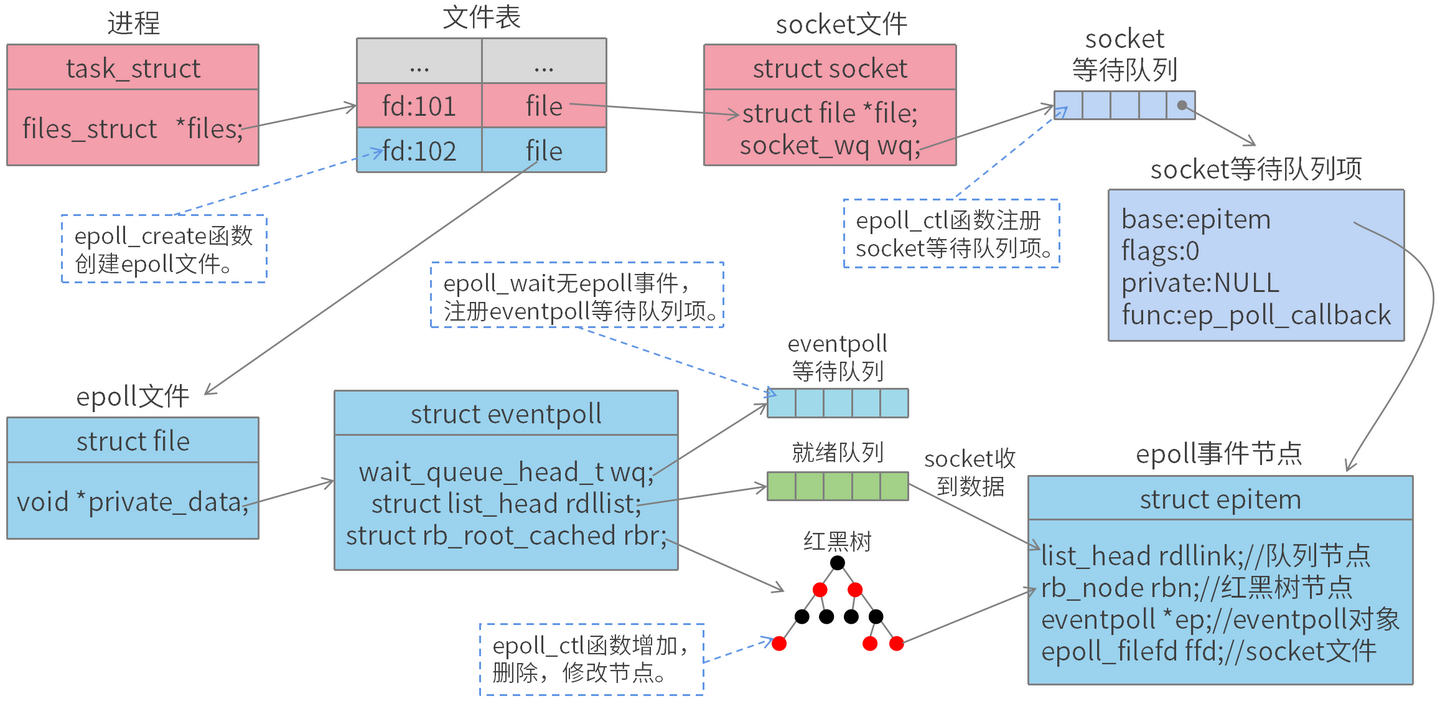
epoll 是一种事件驱动的 I/O 模型,用来替代传统的 select 和 poll 模型。
epoll 内部通过红黑树管理事件,事件有消息时仅返回已就绪的事件集合,无需全部返回。
epoll 的优势在于它可以同时处理大量的文件描述符,而且不会随着文件描述符数量的增加而降低效率。
模式
-
LT 模式:水平触发
- recv 时,只要 fd 还有数据可接收,则每次 epoll_wait 均会返回该 fd 的事件;
- send 时,只要 fd 还有数据可发送,则每次 epoll_wait 均会返回该 fd 的事件;
-
ET 模式:边缘触发
- recv 时,只会提示一次,直到下次再有数据流入之前都不会再提示,无论 fd 中是否还有数据可读;
- send 时,只有再注册 EPOLLOUT 事件,才会再次触发;
总结:
- ET 模式效率要比 LT 模式高
- 小数据推荐使用 ET 模式,大数据推荐使用 LT 模式
- 监听连接推荐使用 LT 模式(因为 accept 函数每次仅能处理一个连接,所以需要持续处理)
函数签名
int epoll_create(int size); // 从 Linux 2.6.8 之后,size 参数被忽略不使用,但为了兼容旧版,确保 size > 0
int epoll_create1(int flags); // 当 flags 等于 0 时,效果等于 epoll_create
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);示例代码(仅示例非阻塞模式下读取事件)
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/signal.h>
#include <sys/wait.h>
#include <sys/sendfile.h>
#include <sys/epoll.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <iostream>
#include <vector>
#include <unordered_map>
#include <algorithm>
int main() {
int sock_fd = ::socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
if (sock_fd == -1) { // 创建 socket 失败
std::cerr << "socket failed: " << errno << std::endl;
return -1;
}
// 设置为非阻塞模式
::fcntl(sock_fd, F_SETFL, ::fcntl(sock_fd, F_GETFL) | O_NONBLOCK);
struct sockaddr_in addr;
::memset(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET;
if (::inet_pton(AF_INET, "127.0.0.1", &(addr.sin_addr)) != 1) {
addr.sin_addr.s_addr = ::inet_addr("127.0.0.1");
}
addr.sin_port = htons(3000);
if (::bind(sock_fd, reinterpret_cast<struct sockaddr*>(&addr), sizeof(addr)) == -1) {
std::cerr << "bind failed" << errno << std::endl;
::close(sock_fd);
return -1;
}
if (::listen(sock_fd, 5) == -1) {
std::cerr << "listen failed" << errno << std::endl;
::close(sock_fd);
return -1;
}
int epfd = ::epoll_create(10);
if (epfd == -1) {
std::cerr << "epoll_create failed" << errno << std::endl;
::close(sock_fd);
return -1;
}
struct epoll_event sock_event = {
.events = EPOLLIN,
.data = { .fd = sock_fd },
};
if (::epoll_ctl(epfd, EPOLL_CTL_ADD, sock_fd, &sock_event) == -1) {
std::cerr << "epoll_ctl failed" << errno << std::endl;
::close(epfd);
::close(sock_fd);
return -1;
}
std::cout << "server started..." << std::endl;
std::unordered_map<int, std::string> client_fds;
while (1) {
std::vector<struct epoll_event> events(1024);
int res = ::epoll_wait(epfd, events.data(), events.size(), -1);
if (res == -1) {
if (errno == EINTR) {
continue;
}
std::cerr << "poll failed" << errno << std::endl;
break;
}
if (res == 0) {
continue;
}
events.resize(res);
for (auto& event: events) {
// 检测读事件
if (event.events & EPOLLIN) {
if (event.data.fd == sock_fd) {
while (1) {
struct sockaddr_in client_addr;
socklen_t client_addr_len = sizeof(sockaddr_in);
int client_fd = ::accept(sock_fd, reinterpret_cast<struct sockaddr*>(&client_addr), &client_addr_len);
if (client_fd == -1) {
if (errno != EAGAIN && errno != EWOULDBLOCK) {
std::cerr << "accept failed: " << errno << std::endl;
}
break;
}
// 设置为非阻塞模式
::fcntl(client_fd, F_SETFL, ::fcntl(client_fd, F_GETFL) | O_NONBLOCK);
char ip_str[INET_ADDRSTRLEN] = {0};
inet_ntop(AF_INET, &(client_addr.sin_addr), ip_str, sizeof(client_addr));
std::string addr = ip_str; addr += ":" + std::to_string(ntohs(client_addr.sin_port));
std::cout << "accept: " << addr << std::endl;
struct epoll_event client_event = {
.events = EPOLLIN, .data = { .fd = client_fd }
};
if (::epoll_ctl(epfd, EPOLL_CTL_ADD, client_fd, &client_event) == -1) {
::close(client_fd);
continue;
}
client_fds.emplace(client_fd, std::move(addr));
}
} else {
std::string addr = client_fds[event.data.fd];
std::string rdata;
while (1) {
char buf[1024] = {0};
ssize_t rsize = ::recv(event.data.fd, buf, 1024, 0);
if (rsize == -1 || rsize == 0) {
if ((errno != EAGAIN && errno != EWOULDBLOCK) || rsize == 0) {
std::cout << "close " << addr << " connect" << std::endl;
client_fds.erase(event.data.fd);
::epoll_ctl(epfd, EPOLL_CTL_DEL, event.data.fd, NULL);
::close(event.data.fd);
}
break;
}
rdata += std::string(buf, rsize);
}
if (!rdata.empty()) {
std::cout << "Client(" << addr << "): " << rdata << std::endl;
std::cout << "Server: " << rdata << std::endl;
::send(event.data.fd, rdata.data(), rdata.size(), 0);
}
}
} else if (event.events & EPOLLHUP) {
::epoll_ctl(epfd, EPOLL_CTL_DEL, event.data.fd, NULL);
::close(event.data.fd);
}
}
}
for (auto&& [i, addr]: client_fds) {
::close(i);
}
::close(epfd);
::close(sock_fd);
return 0;
}select、poll、epoll 对比
| 对比项 | select | poll | epoll |
|---|---|---|---|
| 事件对象存储方式 | 位图 | 链表+数组 | 红黑树 |
| 底层实现 | 轮询方式,每次调用需要从内核空间拷贝全部事件至用户空间 | 轮询方式,每次调用需要从内核空间拷贝全部事件至用户空间 | 回调通知方式,每次调用只需从内核空间拷贝就绪事件至用户空间 |
| 最大连接数 | 1024 | 理论上无限制(由系统资源决定) | 理论上无限制(由系统资源决定) |
| 是否适用于高并发场景 | 否,随着连接数增加,性能线性下降 | 否,随着连接数增加,性能线性下降 | 是,随着连接数增加,性能无明显递减 |
| 编程难度 | 低 | 低 | 中 |
异步 I/O
io_uring
io_uring 是一个 Linux 内核的异步 I/O 框架,提供高性能操作,通过减少系统调用和上下文切换带来的开销提高性能。
io_uring 通过使用环形缓冲区和事件驱动的方式来实现高效的异步 I/O 操作。
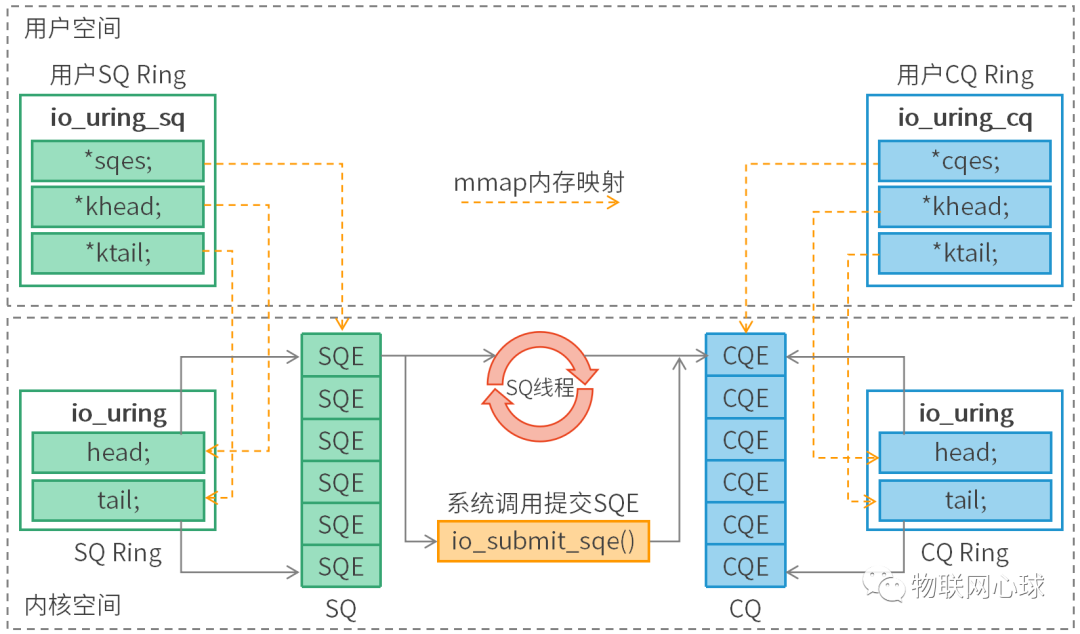
使用方式
-
请求
- 应用创建 SQ entries(SQE),更新 SQ tail;
- 内核消费 SQE,更新 SQ head;
-
完成
- 内核为完成的一个或多个请求创建 CQ entries(CQE),更新 CQ tail;
- 应用消费 CQE,更新 CQ header;
- 完成事件(completion events)可能以任意顺序到达,但总是与特定的 SQE 相关联;
- 消费 CQE 过程无需切换到内核态;
模式
-
中断驱动模式(interrupt driven)
默认模式。可通过 io_uring_enter() 提交 I/O 请求,然后直接检查 CQ 状态判断是否完成。
-
轮询模式(polled)
Busy-waiting for an I/O completion,而不是通过异步 IRQ(Interrupt Request)接收通知。
这种模式需要文件系统(如果有)和块设备支持轮询功能。 相比中断驱动方式,这种方式延迟更低(连系统调用都省了), 但可能会消耗更多 CPU 资源。
目前,只有指定了 O_DIRECT 打开的文件描述符,才能使用这种模式。当一个读或写请求提交给轮询上下文(polled context)之后,应用必须调用 io_uring_enter() 来轮询 CQ 队列,判断请求是否已经完成。
对一个 io_uring 实例来说,不支持混合使用轮询和非轮询模式。
-
内核轮询模式(kernel polled)
这种模式中,会创建一个内核线程(kernel thread)来执行 SQ 的轮询工作。
使用这种模式的 io_uring 实例, 应用无需切到到内核态就能触发(issue)I/O 操作。 通过 SQ 来提交 SQE,以及监控 CQ 的完成状态,应用无需任何系统调用,就能提交和收割 I/O(submit and reap I/Os)。
如果内核线程的空闲时间超过了用户的配置值,它会通知应用,然后进入 idle 状态。 这种情况下,应用必须调用 io_uring_enter() 来唤醒内核线程。如果 I/O 一直很繁忙,内核线程是不会 sleep 的。
系统调用 API
// 这个系统调用
// 1. 创建一个 SQ 和一个 CQ,
// 2. queue size 至少 entries 个元素,
// 3. 返回一个文件描述符,随后用于在这个 io_uring 实例上执行操作。
// SQ 和 CQ 在应用和内核之间共享,避免了在初始化和完成 I/O 时(initiating and completing I/O)拷贝数据。
int io_uring_setup(unsigned int entries, struct io_uring_params *p);
// 这个系统调用用于异步 I/O 的文件或用户缓冲区(files or user buffers)
int io_uring_register(unsigned int fd, unsigned int opcode, const void *arg, unsigned int nr_args);
// 这个系统调用用于初始化和完成(initiate and complete)I/O,使用共享的 SQ 和 CQ。 单次调用同时执行:
// 1. 提交新的 I/O 请求
// 2. 等待 I/O 完成
int io_uring_enter(unsigned int fd, unsigned int to_submit, unsigned int min_complete, unsigned int flags, sigset_t *sig);
int io_uring_enter2(unsigned int fd, unsigned int to_submit, unsigned int min_complete, unsigned int flags, sigset_t *sig, size_t sz);用户空间库(liburing)
liburing 提供了一些简单的高层 API,上层应用无需直接调用系统调用,直接调用该库函数即可。
示例代码(Linux 官方示例)
#include <stdio.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <sys/ioctl.h>
#include <sys/syscall.h>
#include <sys/mman.h>
#include <sys/uio.h>
#include <linux/fs.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#include <stdatomic.h>
#include <linux/io_uring.h>
#define QUEUE_DEPTH 1
#define BLOCK_SZ 1024
/* Macros for barriers needed by io_uring */
#define io_uring_smp_store_release(p, v) \
atomic_store_explicit((_Atomic typeof(*(p)) *)(p), (v), \
memory_order_release)
#define io_uring_smp_load_acquire(p) \
atomic_load_explicit((_Atomic typeof(*(p)) *)(p), \
memory_order_acquire)
int ring_fd;
unsigned *sring_tail, *sring_mask, *sring_array,
*cring_head, *cring_tail, *cring_mask;
struct io_uring_sqe *sqes;
struct io_uring_cqe *cqes;
char buff[BLOCK_SZ];
off_t offset;
/*
* System call wrappers provided since glibc does not yet
* provide wrappers for io_uring system calls.
* */
int io_uring_setup(unsigned entries, struct io_uring_params *p)
{
return (int) syscall(__NR_io_uring_setup, entries, p);
}
int io_uring_enter(int ring_fd, unsigned int to_submit,
unsigned int min_complete, unsigned int flags)
{
return (int) syscall(__NR_io_uring_enter, ring_fd, to_submit,
min_complete, flags, NULL, 0);
}
int app_setup_uring(void) {
struct io_uring_params p;
void *sq_ptr, *cq_ptr;
/* See io_uring_setup(2) for io_uring_params.flags you can set */
memset(&p, 0, sizeof(p));
ring_fd = io_uring_setup(QUEUE_DEPTH, &p);
if (ring_fd < 0) {
perror("io_uring_setup");
return 1;
}
/*
* io_uring communication happens via 2 shared kernel-user space ring
* buffers, which can be jointly mapped with a single mmap() call in
* kernels >= 5.4.
*/
int sring_sz = p.sq_off.array + p.sq_entries * sizeof(unsigned);
int cring_sz = p.cq_off.cqes + p.cq_entries * sizeof(struct io_uring_cqe);
/* Rather than check for kernel version, the recommended way is to
* check the features field of the io_uring_params structure, which is a
* bitmask. If IORING_FEAT_SINGLE_MMAP is set, we can do away with the
* second mmap() call to map in the completion ring separately.
*/
if (p.features & IORING_FEAT_SINGLE_MMAP) {
if (cring_sz > sring_sz)
sring_sz = cring_sz;
cring_sz = sring_sz;
}
/* Map in the submission and completion queue ring buffers.
* Kernels < 5.4 only map in the submission queue, though.
*/
sq_ptr = mmap(0, sring_sz, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_POPULATE,
ring_fd, IORING_OFF_SQ_RING);
if (sq_ptr == MAP_FAILED) {
perror("mmap");
return 1;
}
if (p.features & IORING_FEAT_SINGLE_MMAP) {
cq_ptr = sq_ptr;
} else {
/* Map in the completion queue ring buffer in older kernels separately */
cq_ptr = mmap(0, cring_sz, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_POPULATE,
ring_fd, IORING_OFF_CQ_RING);
if (cq_ptr == MAP_FAILED) {
perror("mmap");
return 1;
}
}
/* Save useful fields for later easy reference */
sring_tail = sq_ptr + p.sq_off.tail;
sring_mask = sq_ptr + p.sq_off.ring_mask;
sring_array = sq_ptr + p.sq_off.array;
/* Map in the submission queue entries array */
sqes = mmap(0, p.sq_entries * sizeof(struct io_uring_sqe),
PROT_READ | PROT_WRITE, MAP_SHARED | MAP_POPULATE,
ring_fd, IORING_OFF_SQES);
if (sqes == MAP_FAILED) {
perror("mmap");
return 1;
}
/* Save useful fields for later easy reference */
cring_head = cq_ptr + p.cq_off.head;
cring_tail = cq_ptr + p.cq_off.tail;
cring_mask = cq_ptr + p.cq_off.ring_mask;
cqes = cq_ptr + p.cq_off.cqes;
return 0;
}
/*
* Read from completion queue.
* In this function, we read completion events from the completion queue.
* We dequeue the CQE, update and head and return the result of the operation.
* */
int read_from_cq() {
struct io_uring_cqe *cqe;
unsigned head;
/* Read barrier */
head = io_uring_smp_load_acquire(cring_head);
/*
* Remember, this is a ring buffer. If head == tail, it means that the
* buffer is empty.
* */
if (head == *cring_tail)
return -1;
/* Get the entry */
cqe = &cqes[head & (*cring_mask)];
if (cqe->res < 0)
fprintf(stderr, "Error: %s\n", strerror(abs(cqe->res)));
head++;
/* Write barrier so that update to the head are made visible */
io_uring_smp_store_release(cring_head, head);
return cqe->res;
}
/*
* Submit a read or a write request to the submission queue.
* */
int submit_to_sq(int fd, int op) {
unsigned index, tail;
/* Add our submission queue entry to the tail of the SQE ring buffer */
tail = *sring_tail;
index = tail & *sring_mask;
struct io_uring_sqe *sqe = &sqes[index];
/* Fill in the parameters required for the read or write operation */
sqe->opcode = op;
sqe->fd = fd;
sqe->addr = (unsigned long) buff;
if (op == IORING_OP_READ) {
memset(buff, 0, sizeof(buff));
sqe->len = BLOCK_SZ;
}
else {
sqe->len = strlen(buff);
}
sqe->off = offset;
sring_array[index] = index;
tail++;
/* Update the tail */
io_uring_smp_store_release(sring_tail, tail);
/*
* Tell the kernel we have submitted events with the io_uring_enter()
* system call. We also pass in the IOURING_ENTER_GETEVENTS flag which
* causes the io_uring_enter() call to wait until min_complete
* (the 3rd param) events complete.
* */
int ret = io_uring_enter(ring_fd, 1,1,
IORING_ENTER_GETEVENTS);
if(ret < 0) {
perror("io_uring_enter");
return -1;
}
return ret;
}
int main(int argc, char *argv[]) {
int res;
/* Setup io_uring for use */
if(app_setup_uring()) {
fprintf(stderr, "Unable to setup uring!\n");
return 1;
}
/*
* A while loop that reads from stdin and writes to stdout.
* Breaks on EOF.
*/
while (1) {
/* Initiate read from stdin and wait for it to complete */
submit_to_sq(STDIN_FILENO, IORING_OP_READ);
/* Read completion queue entry */
res = read_from_cq();
if (res > 0) {
/* Read successful. Write to stdout. */
submit_to_sq(STDOUT_FILENO, IORING_OP_WRITE);
read_from_cq();
} else if (res == 0) {
/* reached EOF */
break;
}
else if (res < 0) {
/* Error reading file */
fprintf(stderr, "Error: %s\n", strerror(abs(res)));
break;
}
offset += res;
}
return 0;
}